This is a very good question, so I decided to write a very detailed article about this topic on my blog.
Database table model
Let’s assume we have the following two tables in our database, that form a one-to-many table relationship.
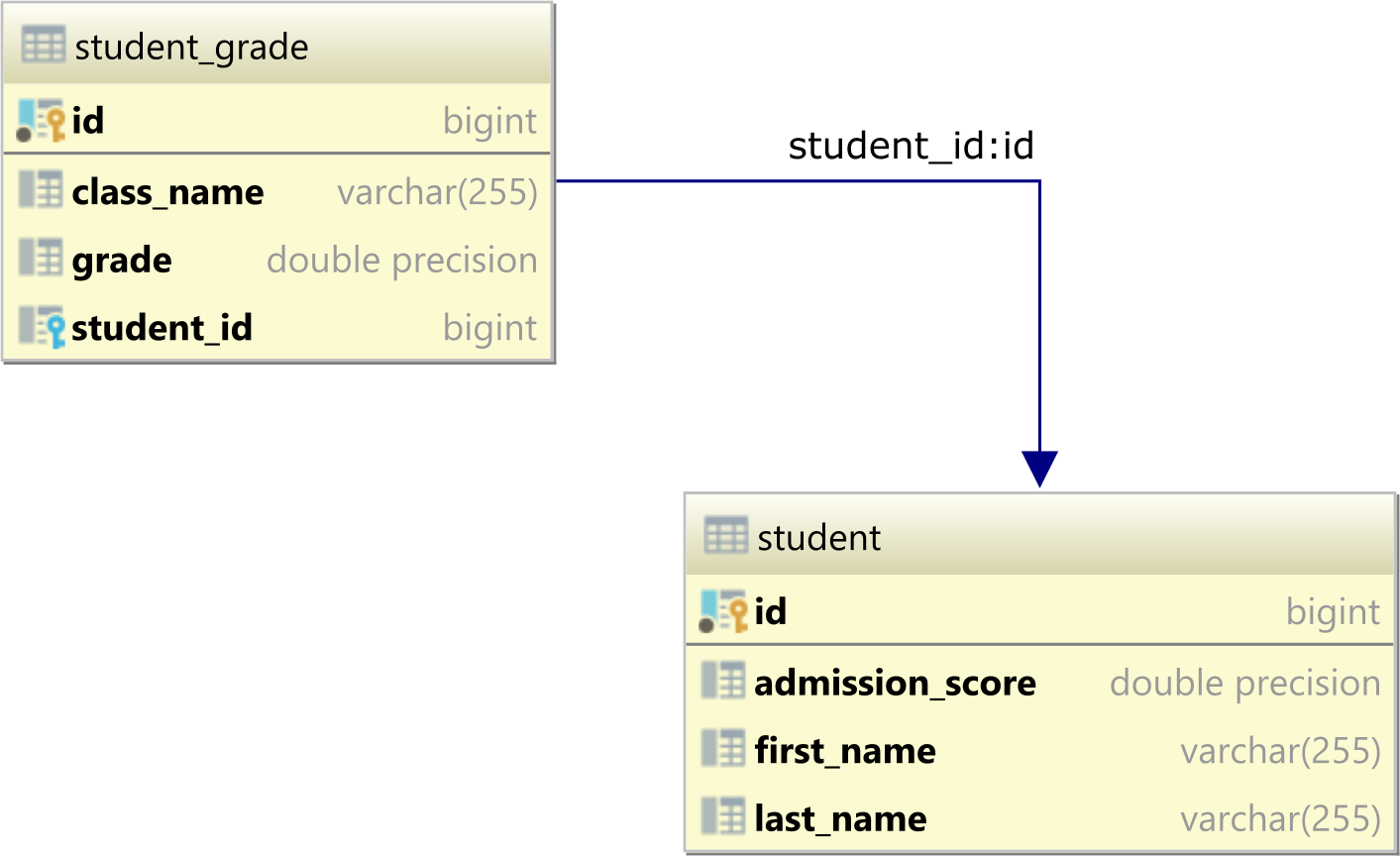
The student table is the parent, and the student_grade is the child table since it has a student_id Foreign Key column referencing the id Primary Key column in the student table.
The student table contains the following two records:
| id | first_name | last_name | admission_score ||----|------------|-----------|-----------------|| 1 | Alice | Smith | 8.95 || 2 | Bob | Johnson | 8.75 |
And, the student_grade table stores the grades the students received:
| id | class_name | grade | student_id ||----|------------|-------|------------|| 1 | Math | 10 | 1 || 2 | Math | 9.5 | 1 || 3 | Math | 9.75 | 1 || 4 | Science | 9.5 | 1 || 5 | Science | 9 | 1 || 6 | Science | 9.25 | 1 || 7 | Math | 8.5 | 2 || 8 | Math | 9.5 | 2 || 9 | Math | 9 | 2 || 10 | Science | 10 | 2 || 11 | Science | 9.4 | 2 |
SQL EXISTS
Let’s say we want to get all students that have received a 10 grade in Math class.
If we are only interested in the student identifier, then we can run a query like this one:
SELECT student_grade.student_idFROM student_gradeWHERE student_grade.grade = 10 AND student_grade.class_name = 'Math'ORDER BY student_grade.student_id
But, the application is interested in displaying the full name of a student, not just the identifier, so we need info from the student table as well.
In order to filter the student records that have a 10 grade in Math, we can use the EXISTS SQL operator, like this:
SELECT id, first_name, last_nameFROM studentWHERE EXISTS ( SELECT 1 FROM student_grade WHERE student_grade.student_id = student.id AND student_grade.grade = 10 AND student_grade.class_name = 'Math')ORDER BY id
When running the query above, we can see that only the Alice row is selected:
| id | first_name | last_name ||----|------------|-----------|| 1 | Alice | Smith |
The outer query selects the student row columns we are interested in returning to the client. However, the WHERE clause is using the EXISTS operator with an associated inner subquery.
The EXISTS operator returns true if the subquery returns at least one record and false if no row is selected. The database engine does not have to run the subquery entirely. If a single record is matched, the EXISTS operator returns true, and the associated other query row is selected.
The inner subquery is correlated because the student_id column of the student_grade table is matched against the id column of the outer student table.
SQL NOT EXISTS
Let’s consider we want to select all students that have no grade lower than 9. For this, we can use NOT EXISTS, which negates the logic of the EXISTS operator.
Therefore, the NOT EXISTS operator returns true if the underlying subquery returns no record. However, if a single record is matched by the inner subquery, the NOT EXISTS operator will return false, and the subquery execution can be stopped.
To match all student records that have no associated student_grade with a value lower than 9, we can run the following SQL query:
SELECT id, first_name, last_nameFROM studentWHERE NOT EXISTS ( SELECT 1 FROM student_grade WHERE student_grade.student_id = student.id AND student_grade.grade < 9)ORDER BY id
When running the query above, we can see that only the Alice record is matched:
| id | first_name | last_name ||----|------------|-----------|| 1 | Alice | Smith |
So, the advantage of using the SQL EXISTS and NOT EXISTS operators is that the inner subquery execution can be stopped as long as a matching record is found.
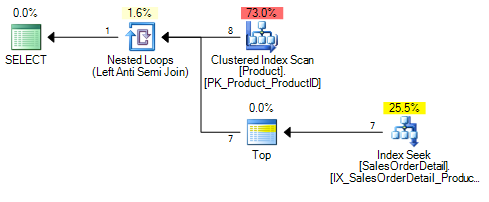
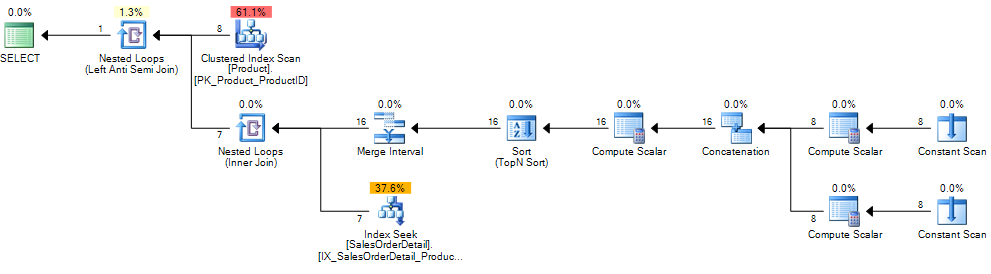

NOT INquery:SELECT "A".* FROM "A" WHERE "A"."id" NOT IN (SELECT "B"."Aid" FROM "B" WHERE "B"."Uid" = 2)is almost 30 times as fast as thisNOT EXISTS:SELECT "A".* FROM "A" WHERE (NOT (EXISTS (SELECT 1 FROM "B" WHERE "B"."user_id" = 2 AND "B"."Aid" = "A"."id")))– Phương Nguyễn Dec 4 '12 at 19:06